Agentic coding, in practice: an operating model for AI-native software teams

AI-native software development is not a tool. It is an operating model. The IDE plugin, the chat window, the autocomplete: those were tools. Agentic coding is the shape of the work itself.
"Agentic coding" names the thing precisely: an agent that plans, reads, writes, runs tests, and reports back, inside a program built to keep it honest. The agent is a worker. The harness is the workplace. The engineer is closer to a director than a typist.
When a team commits to this in earnest, eight levers move at once:
- Harness. The program around the model
- Context. What the agent is allowed to see
- Workflows. How the work gets delegated
- Quality. How failures get caught
- Evals. How you know it is still working
- Security. The new attack surface
- Economics. What an agent run actually costs
- Lock-in & teams. Where the dependency settles and how the role changes
Most teams pick up one or two, declare victory, and wonder why productivity stalls. The gains compound when the levers are pulled together.
This article walks all eight. Written from inside Appliscale, running this on client work. Where a tool earns its place, we name it. Where a practice has not landed yet, we say so. Where we are uneasy, we admit it.
Part 1: The stack
What a coding harness actually is
A coding harness is the program that runs the AI model and gives it tools. The model alone reads and writes text. The harness lets it act.
What a harness provides:
- File read and write across a codebase
- Shell command execution, tests, build tools
- Web search and documentation fetch
- Git operations (commit, branch, pull request)
- MCP integrations (Slack, Linear, databases)
- Permission prompts before destructive actions
- Conversation memory across turns
- Sub-agents and parallel task spawning
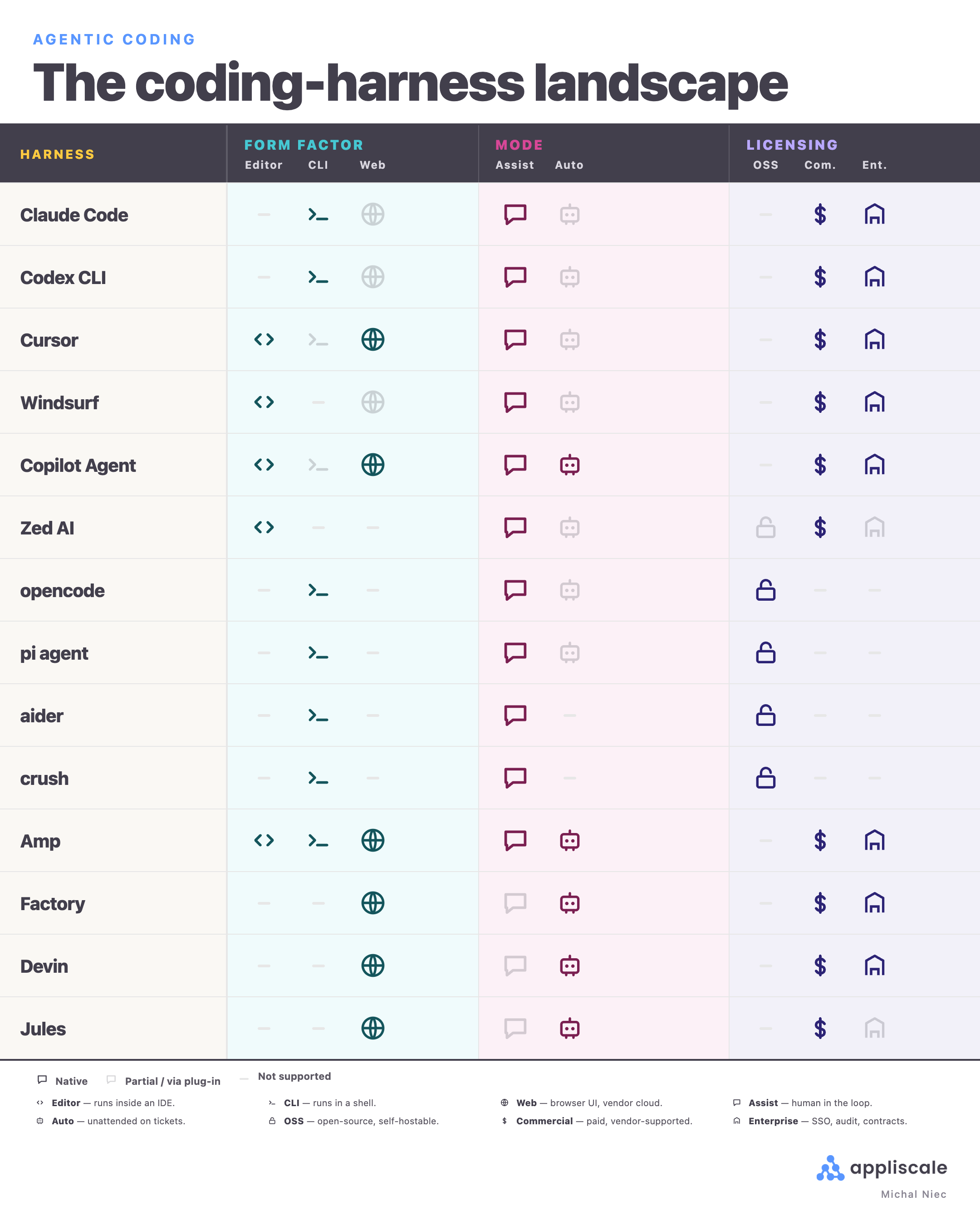
Three categories in 2026:
| Category | Where it runs | Examples |
|---|---|---|
| IDE-integrated | Inside the editor | Cursor, Windsurf, GitHub Copilot Agent, Zed AI |
| CLI / terminal | In a terminal window | Claude Code, Codex CLI, opencode, aider, crush, pi |
| Autonomous / cloud | On a remote server, unattended | Devin, Factory, Amp, Jules |
Licensing splits cleanly:
- Open-source (opencode, aider, crush, pi): model-agnostic, auditable, swap providers freely.
- Commercial (Claude Code, Codex, Cursor, Windsurf, Devin, Factory, Amp, Jules): polished UX, vendor-managed defaults, an opinionated path you cannot fully inspect.
In our teams, most senior engineers run two or three harnesses in parallel and switch by task: one CLI for deep work, one IDE-integrated for editing, occasionally a cloud-autonomous run for a batch of tickets.
Why the harness matters more than the model. The harness decides:
- What files and tools the agent can access
- Which actions require human approval
- How context is loaded and cached
- Whether code or prompts leave your network
- Which model(s) get called and when
That last one is the trick: a harness can route planning to one model, code-writing to another, review to a third, all without you noticing.
Same model, very different output, depending on the program around it.
Context engineering: what the agent is allowed to see

An AI agent has no memory of your repository. Every conversation starts blank. Deciding what it sees is called context engineering. Every harness bets differently. The field is still being figured out.
Two layers:
The harness handles retrieval automatically:
- Direct file reading. Opens files, follows imports. Simple, slow on large repos.
- Code search. Keyword match. Fast, misses what is not named the way it searched.
- RAG. Snippets indexed by meaning. Powerful, drifts as code changes.
- Code graph. Map of what calls what. Accurate for refactors, expensive to build.
- Compaction. Older history summarised when the window fills.
- Sub-agents. Heavy exploration in a separate window, only the conclusion comes back.
The human levers, where you actually steer:
- Conventions file. Always-on rules (CLAUDE.md, AGENTS.md). Biggest behaviour change per hour invested.
- Skills. Conditional instructions loaded only when relevant.
- Library knowledge. Mastra ships an MCP for its docs; Vercel publishes an official
agent-skillsReact skill. Agents write against the real API instead of reverse-engineering it. - Extensions.
pi context-modesandboxes tool output into a local DB;graphifyturns a repo into a queryable code graph.
When we test a new harness, we bring our usual set of MCP servers, CLIs, and skills along. Most of it plugs in and works as is. That layer stays portable.
Protocol portability is not behavioural portability. A tool tuned to one model's pacing can loop or hallucinate under another. Every harness swap is also a small re-tuning.
Context engineering is where your team's judgment goes. the part the model cannot guess.
Part 2: How the work gets done
Four ways to delegate to an agent
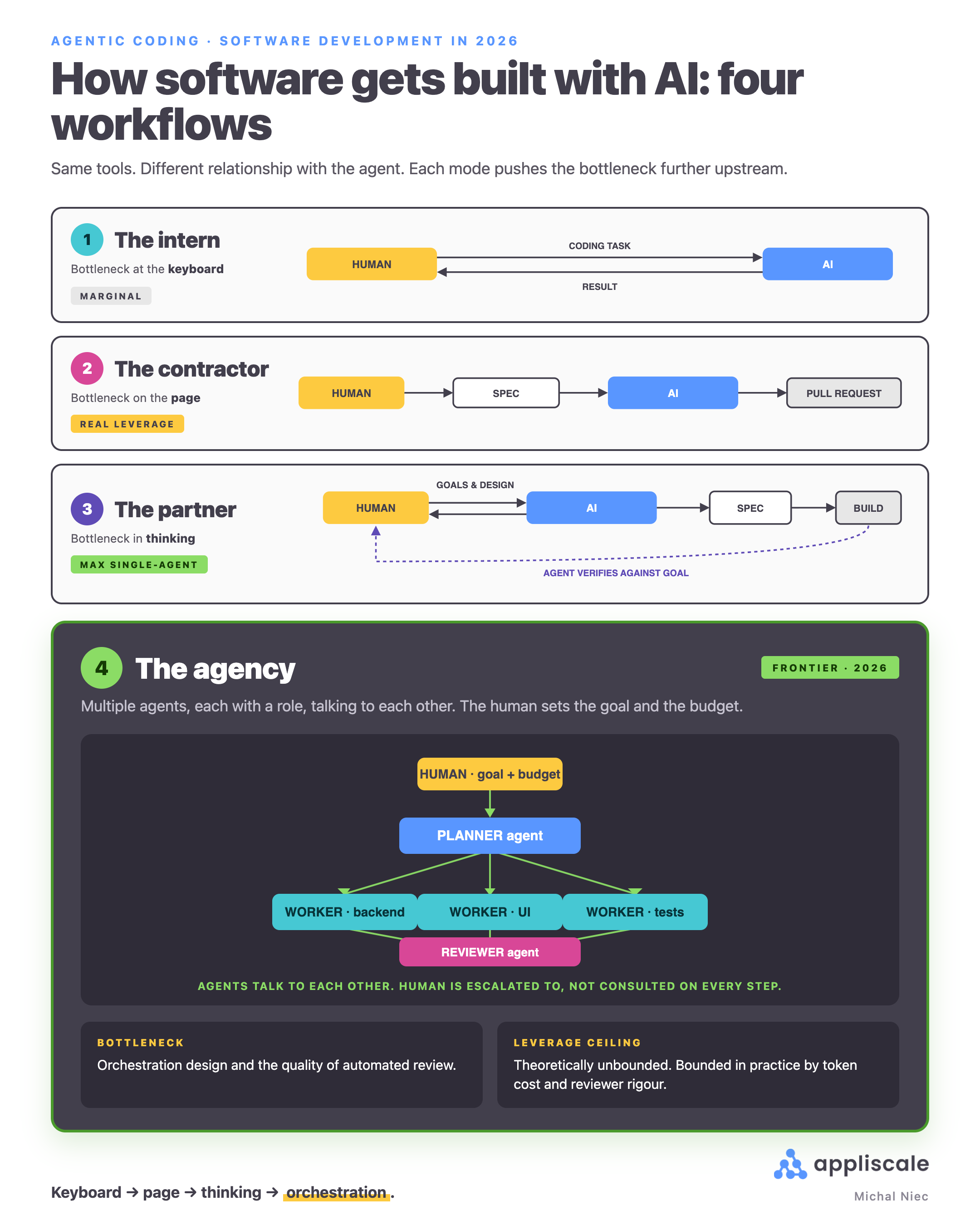
Same tools, dramatically different leverage. The easiest frame: how would you delegate this to a person, or a team?
-
Intern. Small, scoped tasks on request ("write a test for this", "rename this everywhere"). The engineer is still writing the code.
- Bottleneck: how fast one person dispatches tasks.
- Leverage: 10–30 percent uplift.
- Most non-engineers still think this is AI coding. It is the smallest of the four.
-
Contractor. The engineer writes a spec; the agent delivers end to end (files, tests, fixes, PR). The engineer reviews the result, not the keystrokes.
- Bottleneck: quality of the spec.
- Leverage: 3–10× once patterns are established.
-
Partner. The engineer starts with an outcome, not a spec. The agent asks clarifying questions, proposes approaches, flags constraints. They agree on a plan, then build.
- Bottleneck: clarity of thinking about the problem.
- Leverage: maximum on a single feature.
- Most of our senior engineers have quietly converged here for individual features.
-
Agency. Multiple agents talking to each other. The engineer sets goal and budget; agents organise (planner → workers → reviewer).
- Bottleneck: orchestration design and reviewer quality.
- Leverage: theoretically unbounded, capped by token cost and verifiability.
- Where most spectacular demos and spectacular failures come from.
Each mode pushes the bottleneck further upstream:
| Mode | Bottleneck moves to… |
|---|---|
| Intern | The keyboard |
| Contractor | The page (the brief) |
| Partner | The thinking (the framing) |
| Agency | The orchestration (the reviewer) |
Same models, same headcount. Teams operating at the higher modes outproduce teams stuck at the lower ones by an order of magnitude. When someone says "we use AI for coding", the real question is which of the four. If they cannot answer, they are in mode one.
Four ways agents fail, and how teams contain it

Code that compiles and passes tests is not automatically correct. Four failure modes show up often enough to name:
- Hallucination. The agent invents a function, API, or library that does not exist. The code looks plausible and can pass shallow tests.
- Reinvention. Bespoke code for a problem an existing library already solves. Maintenance cost compounds quietly, surfacing months later as duplicated logic.
- Verbosity. More files, abstractions, defensive branches than necessary. Review time and long-term load go up.
- Sycophancy. The agent agrees with the human's hypothesis even when it is wrong and pursues the wrong direction confidently. Harder to spot than hallucination.
The containment stack. four layers, each catching a different class of failure:
| Layer | What it catches | Notes |
|---|---|---|
| Reviewer agent | Hallucinations, reinvention | In-loop sub-agent or external PR-review service. CodeRabbit, Greptile, Qodo. Independence is the point. |
| Plan-and-diff review | Scope drift, wrong direction | Human reviews plan up front and diff at the end, not every line. |
| Linters, type checks | Syntax-level errors | The static analysis you already run. |
| Convention rules | Verbosity, off-pattern code | Explicit rules in the conventions file. |
We use external PR-review services on top of in-loop reviewer agents because the independence is the point: a second model reading the diff fresh catches what the author agent missed.
Static analysis catches syntax, not judgment, and judgment is what fails. Passing tests is the floor, not the proof.
Evals: how you know it's still working

Most teams treat agent output like normal code. It is not.
Test vs eval:
- A test checks your code. Deterministic. Pass or fail.
- An eval checks the agent system (model + harness + conventions + skills + sub-agent prompts). Statistical. Run N times, measure a pass rate.
What an eval is, concretely. A fixed set of realistic tasks from your own repo, each with a checkable success criterion. "Add pagination to this endpoint." Did the tests pass? Did the diff touch the right files? Freeze the set, re-run on demand.
The trigger is change:
- A model upgrade (Opus 4.6 → 4.7)
- A harness or harness-version change
- An edit to the conventions file, a new skill, a changed sub-agent prompt
Without an eval, every one of those is a blind change. The eval turns "feels better" into a number, and lets you gate a rollout. We track our coding evals against every model and harness bump. without that, every upgrade is a vibe.
Two kinds, often confused:
- Public benchmarks (SWE-bench Verified, Terminal-bench): sanity-check vendor claims. Say nothing about your codebase.
- Internal evals: your tasks, your repo, your definition of correct. The only signal that matters. Almost nobody has them yet.
Rigor scales. From one golden task re-run by hand, up to a CI suite scored partly by an LLM-as-judge. Start with one task. One is infinitely more than zero.
Without evals, every upgrade is a blind change.
Part 3: The constraints
Security: the new attack surface

Everyone agrees the attack surface is bigger. Almost no one agrees on what protects you.
A coding agent is not a chatbot. It reads and writes files, runs shell commands, makes network calls, installs packages, touches version control, calls third-party services. Every one of those is a new way in.
Four attack vectors:
| # | Vector | What it looks like |
|---|---|---|
| 1 | Prompt injection from data | Hidden instructions in a file, web page, ticket, or doc the agent reads. The model cannot reliably tell data from instructions. |
| 2 | Compromised MCP or tool | A third-party server returns malicious output, or quietly exfiltrates the agent's context. |
| 3 | Slopsquatting | Agent hallucinates a package name, attacker registers it with malware, next agent installs it. |
| 4 | Runaway command | The agent runs something destructive (mass delete, runaway cloud spend) with no human in the loop. |
The usual defences:
- Sandbox / container. Worst case is the container, not the machine or production.
- Permission prompts. Before destructive or networked actions.
- Read-only by default. Writes need an allowlist.
- Untrusted-input boundary. Mark external content as data, not instructions.
- MCP allowlist. Audited, pinned, minimal permissions.
- Dependency hygiene. Lockfiles, scanners, private registries, no silent auto-install.
- Audit logs. Every tool call recorded.
On every project we sandbox the agent and treat MCP servers like browser extensions.
The theater problem. A lot of this is starting to feel like security theater. Permission prompts are the clearest case:
- Teams spend the day clicking allow and disallow.
- Yet prompt injection talks the agent into doing the wrong thing inside already-granted permissions.
- An allowlist does not stop an attack that uses only allowed actions.
- Click fatigue makes people approve everything anyway.
Not useless. necessary but not sufficient. Sandboxing limits blast radius whether or not you trust the agent. The rest lowers risk without ever removing it. Anyone selling a fully solved story is selling theater.
The agent has the credentials of an administrator and the judgment of a new hire. Configure access accordingly. Assume the prompt can be turned against you.
What agentic coding actually costs

An agent run costs real money. a few cents for a simple edit to ten dollars or more for a multi-agent build. Economics shift month to month. Treat any number here as a snapshot.
Four cost levers, layered:
- Model size (the foundation). Frontier models (Claude Opus, GPT-5 Pro) run ~10–15× the per-token cost of small models (Haiku, Gemini Flash). Right-size each step.
- Orchestration pattern.
- Single agent, long context. cheapest, simplest.
- Planner + workers + reviewer. 2–5× the cost, better on hard tasks.
- Parallel exploration. expensive, worth it for design work.
- Caching (the layer most teams underuse). Reusing context costs a fraction of recomputing it. 50–80 percent off long-session cost when configured well.
- The harness itself. Same task, very different token volume depending on the harness. Claude Code is capable but not frugal; a wave of harnesses claim to do the same work on a fraction of the tokens. The harness is a cost line item, not a neutral wrapper.
Route by complexity. Plan with a frontier model, execute with a small one, review with a frontier model. "Small model on the inside, big model at the edges." We route this way in our day-to-day, and prompt caching is the single biggest line-item win we have found.
Two ways to pay, both moving:
| Pay per token (API) | Flat subscription (Claude Max) | |
|---|---|---|
| Predictability | Scales linearly with volume | One monthly price |
| Cheaper for | Light or bursty use | Heavy daily use |
| Catch | None major | Usage caps tighten quietly; often tied to provider's own harness |
At team scale this is governance, not just billing. LLM gateways like TrueFoundry sit between engineers and providers to set per-team budgets and enforce token quotas.
Running your own model? Open models (Qwen 3.6) are good enough for real coding now. The hardware is the problem:
| Setup | Up-front cost | Beats $200/mo Claude Max? |
|---|---|---|
| Nvidia DGX Spark | ~$4,000 | No |
| MacBook Pro M5 Max (specced) | $5,000+ | No |
Self-hosting wins on privacy, compliance, or air-gapped work. not cost or quality. That gap is closing.
A flat AI bill across a quarter usually means nobody is optimising.
Part 4: The strategic layer
Where lock-in actually lives

Lock-in is not one thing. It comes in levels:
| Level | Depth | What you actually owe |
|---|---|---|
| Model | Shallow | A setting, if the harness supports more than one provider. Catch: harnesses are tuned to a model, so a swap usually performs worse. |
| Tooling (MCP, CLIs, skills) | Portable | Wiring moves with you. Behaviour does not always come along. |
| Frameworks (Mastra, CrewAI) | Medium | They sit between you and the raw API; can break model-specific tricks. |
| Harness | Deepest | Skills, plugins, routines built around one tool. Plus state: the harness owns your codebase index, vector store, and conversation history. |
| Licensing | Amplifier | Commercial terms steer you onto one harness and one model. |
The Mastra example. Anthropic's prompt caching needs a byte-for-byte identical prefix. A framework that quietly injects a timestamp or a changing memory ID into the payload breaks that match, kills the cache, and the token bill jumps. We hit exactly this with Mastra. The abstraction that saves you work also strips the control you need for model-specific optimisations.
The state hook is the deepest part. Leave a harness and you do not just lose a UI or a subscription. You lose the agent's ingested memory of your repo, and you start from zero context.
Licensing tightens the knot. A provider like Anthropic offers a genuinely generous subscription, but it steers you onto their own harness. The cheap, easy entry quietly becomes the thing you cannot exit.
The lock-in never announces itself. It just quietly becomes the way you work.
Same software engineer, new job

The role is shifting from writer (producing code line by line) to director (defining tasks, briefing agents, reviewing output). Three changes follow.
1. Seniors become the multiplier.
- Plenty of engineers still want to code the old way. The ones who pair experience with orchestration can run several workstreams in parallel.
- 10× and 20× are real now for engineers who lean in.
- Caveat: output scales 10×, maintenance does not. A solo senior replacing a team is also a single point of failure when an AI-built system breaks at 3 AM. Strongest on greenfield, weakest on operations.
2. The junior path is changing.
- Agents now do the simple, scoped code juniors used to learn on.
- The taste paradox: taste is earned by writing code and breaking it. If juniors never do that, where does the judgment to review an agent's work come from? Open problem most teams have not solved.
- At Appliscale, our approach:
- Hire juniors with strong CS background and real ML grounding (universities now teach far more of it).
- Treat them as product engineers from the start. system design and product thinking over coding.
- Pair them with seniors who teach how to deploy and run systems in production.
3. Role boundaries are blurring.
- Our first teams are running end to end with AI assistance through the whole loop: requirements, design, implementation, deployment.
- Each engineer owns a slice of the system, which means far fewer conflicts when code lands.
- Syncs changed too: more brainstorming new features and trading feedback, less status reporting. Motivation is high because the daily output is visible and used by teammates.
About as big a shift as office workers getting computers in the 1980s. Most of the playbook has not been written yet.
How this lands at Appliscale
Eight levers, all moving at once. No team operates them perfectly. The operating model is a set of dials a team learns to turn together, not a configuration anyone arrives at.
What's working for us:
- Route by complexity in daily work: frontier model to plan and review, smaller model to execute.
- First teams running end to end with AI assistance through the whole loop.
- Juniors with CS + ML fundamentals, treated as product engineers from day one.
- Every project sandboxes its agents by default.
- External PR-review services on top of in-loop reviewer agents.
- Prompt caching is the single biggest cost-line win we've found.
What we are still figuring out:
- Internal evals discipline is patchy. Some projects have a frozen task set. Most do not yet.
- The taste paradox for juniors is unresolved. Our path seems to work; we are not certain it scales.
- Claude Code lock-in is real. It is the right tool for now, and we are uneasy about how reliant we have become.
- Pricing caps keep moving, which makes capacity planning a quarterly conversation, not an annual one.
If you are working through any of this in your own team and want to compare notes, get in touch.
The teams that treat agentic coding as an operating model, not a tool, are already pulling ahead.